
The evidence is examined to determine when and where the original Indo-Europeans lived. Based upon this evidence, the probable identity of the first Indo-Europeans is revealed.
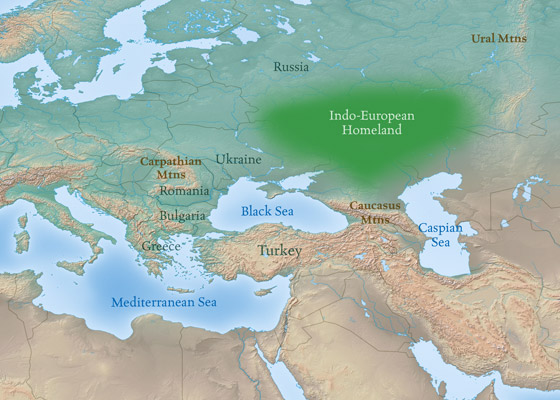
Map Prepared by Louis Henwood (Click Map for Larger Image)
Podcast: Play in new window | Download
Subscribe: RSS
This might be the best podcast I’ve ever listened to. Very addictive. Thank you!
Is there an episode where you focus only on Old English and discuss the loss of inflections (especially on nouns) WITH actual examples?
Cheers!
Thanks! You might want to check out “Episode 53: The End of Endings.” Be aware that the episodes are in chronological order, so you will be skipping ahead in the story.
I agree. Thanks so much! I’m going to use it with my students:)
Hi Kevin,
Thanks for interesting episode. I could understand the reasoning behind last possible date of people speaking PIE. But I couldn’t understand about earliest date. You mentioned that If they had word for wheel or wool than they couldn’t have existed before wheel or wool was in common use. But can’t they increase their vocabulary over time and adopt those words later on. I mean can’t they exist before those inventions?
Regards,
The discussion concerning the PIE time frame was based on the research and analysis used by many historical linguists and scholars, so I relied upon their analysis and time frame. My understanding is that PIE is defined as the language which contains the vocabulary that has been reconstructed from the modern Indo-European daughter languages. Thus, by definition, it has to include the reconstructed words for wheels and wool. Like all languages, PIE would have evolved from an even earlier language, and that earlier form of the language would not have included those words. But again, by definition, that language would have been Pre-PIE, and thus outside of the specific time frame identified by scholars. Since languages evolve gradually and slowly, linguists have to draw arbitrary lines in the sand to distinguish different stages of development. So I think this is just a somewhat arbitrary line in the sand. I hope that make sense.
Hello!
I had the same question as was so well articulated by Bhaumik Shah. Thank you both for the clarification.
I am, Mr. Stroud, gushingly delighted and grateful for the podcast. Rarely have I found learning to be so easy, engaging, and rewarding. I’m hopelessly distracted by the gaps and contradictions that plague so much instruction, and I appreciate very much the thoroughness and coherence of the narrative you present.
I have trouble taking in information — I routinely listen twice to any information-dense input that is good enough to listen through once — so I find your careful framing, including revisitations of earlier explanations and examples, extra-helpful. It aids my learning enormously when I have the chance to predict the end of your sentence, because it’s a recollection of an earlier lesson. Even when I don’t manage to remember the recalled fact before you finish the sentence, the exercise of memory really helps me own the information.
Thank you very much indeed.
Thank you for the feedback. I’m glad you’re enjoying the podcast.
What I got from the wheel example was that a new invention has no specific word. Instead it is described. eg something that goes around describes a wheel.
Just my conjecture.
Ronn
Great podcast. I do have one question. How do we know honey couldn’t have been a traded good from elsewhere rather than a local item?
It’s a question that should really be addressed to a proper historical linguist familiar with Indo-European studies. I am not a historical linguist; I only report their conclusions. My guess is that trade routes were much more limited during the time of the original Indo-Europeans, and there is no evidence to support such a long-range trade in honey. But again, that’s just a guess.
I agree: good question. Modern English existed before aeroplane, internet and transphobic. Much as Mr Stroud deserves praise for his efforts, I think he gets a bit lost in some of these geographic and temporal deductions.
For the record, those are not ‘my’ deductions. And I say that not to deflect blame for questionable theories, but more specifically, not to take credit for the good theories devised by proper linguists who have studied this stuff for decades. I try to convey those theories and ideas as best I can, but it is certainly not my idea that PIE began with wheeled wagons and other technologies mentioned in the episode. As I noted above, linguists draw somewhat arbitrary lines to distinguish different periods of a given language, and one of the lines they draw to distinguish PIE from ‘pre-PIE’ is the presence of wheeled wagons and other technologies.
A proto-language like PIE is defined differently than a modern language like Modern English I think. Overall, there is no strictly linguistic definition for when a language becomes distinct from other languages; it mostly depends on cultural and historic landmarks that often have little or nothing to do with actual changes in the language. In the case of a proto-language, I believe (from what I remember reading – could easily be wring) it’s defined as the latest unified stage of an ancestor language of future distinct languages. So PIE is the latest point in history when the ancestors of Hindi, English, Hittite etc. were spoken as one single language – and at that point it definitely had words for wheel and wool. Anything that came before that point is pre-PIE. Of course, we may have additional details on when the speakers of PIE began to form a singular community based on archeological evidence etc., but that is no longer related to the language.
Love your podcasts. So well-researched and informative.
FYI, “cuneiform” is pronounced koo-NAY-ih-form.
Don’t know if you can answer this: Why did all the people in this area speak the same language (Proto-Indo-European, Indo-European)? It seems strange to me. After all, language has been around for tens of thousands of years.
Along the same lines, as the Indo-Europeans swept eastward, did they replace the earlier peoples by either wiping them out or outnumbering them? Did any of the languages extant in, say India or the Russian steppe, survive, or were words from them incorporated into the now mainly Indo-European-derived forms?
Hi Linda,
I think some of these questions are addressed in the upcoming episodes about the Indo-European migrations. I don’t think most modern linguists think that PIE was the sole language spoken in these regions. It is merely a reconstructed language based on the surviving linguistic evidence. It appears to have been the dominant language, but there were likely other isolated languages being spoken around the same time. The Proto-Germanic language shows a significant influence which appears to be from another long lost language that was spoken in the same proximity.
I don’t know enough about all of the steppe languages, but there are other surviving language families that have their origins in the same general vicinity – including the Caucasian, Uralic and Altaic language families.
I discovered your podcast late but, like many of your listeners, I am enjoy your podcasts which you present in the most engaging manner. On this episode, you talk about PIE’s root to Sanskrit. Dravidian languages have long existed in India before Sanskrit. I am of Dravidian descent and am fiercely protective of Dravidian heritage as it is not appreciated much in India itself.
Hi Mani. Yes, the Dravidian languages are unrelated to the Indo-European languages and are still spoken by millions of people in India – especially in the south. I am not sure if the Dravidian languages had any influence on the development of Sanskrit. I would be curious to find out.
Kevin, your podcast is a gem! Thank you for sharing your insights.
A wheeled toy model from Qoser in Kurdistan is 7500 years old:
https://ktwop.com/2012/02/26/earliest-evidence-of-the-wheel-7500-year-old-toy-car-found/
The proximity of this find to the Gobeklie Tepe monuments in Anatolia is very interesting. It is logical that the wheel would be invented where people needed to carry objects over long distances and domesticated animals to do that. It’s also logical that they were close enough to wooded terrain to obtain wood to built wheels. Transition land bordering steppe and forest in climate conditions @ 10,000-20,000 BC sounds right.
Wonder how close is the Kurdish language(s) to the proto Indo European root?
Interesting. I wonder how confident scholars are in the proposed date of that toy. It is an amazing find if it is really that old. As far as Kurdish is concerned, it is an Indo-European language, but I don’t know how close it is to PIE. Given that it is part of the Indo-Iranian sub-family, I suspect that it is no more closely related than any of those other related languages.
Re a wheeled toy. Wheeled toys have been found in pre-Columbian sites in South or Central America but the wheel was never used for full sized carts of any sort. I think archaeologists guess that the wheel never progressed beyond a toy because there were no domestic animals that could have pulled carts. So perhaps, a wheeled cart was made as a toy in Kurdistan long before it took off, awaiting a practical draft animal.
Just a thought.
In reference to the toy, here’s the museum that apparently has it: http://www.mardinmuzesi.gov.tr/; I’m having trouble finding any reference to the car on their website, however.
In reference to Kurdish, my guess is that it started to appear as a distinct language around the 5th century CE, but I don’t really know; that’s when Median (the oldest Northwest Iranian language we have record of) started to disappear. But Median itself is not well understood, so that doesn’t provide much clarity. Encyclopædia Iranica has some insights, though: http://www.iranicaonline.org/articles/kurdish-language-i
In summary, Kevin’s answer is best: “Given that it is part of the Indo-Iranian sub-family, I suspect that it is no more closely related than any of those other related languages.”
I’m delighted to have many more of your podcasts left to listen to. There are so many aspects of this series that interest me and I love the level of detail you have chosen to give us. Your voice and the speed at which you read seem just right for the material.
Thanks! I’m glad you’re enjoying it. And you’ve got a long way to go. 🙂
If only the archaeogenetic evidence was include as well.
This episode was actually prepared and posted back in 2012 before several of the most recent DNA studies were released related to early European migrations. As you may know, these recent studies have tended to confirm that there was an early migration of people from the Eurasian steppe region into western Europe during a timeframe that corresponds to the spread of the Indo-European languages. I do mention some of those more recent studies in a later episode.
Kevin, this podcast is wonderful so far, and this episode particularly enlightening. Thank you so much.
I’ve had a rough awareness for decades of the framework of the relations among Indo-European languages – I’m a native speaker of American southern English, like you, and I studied French and German in high school, majored in Latin and Greek and threw in a year of college Russian. But it was only from learning Japanese (by living and working in Japan, not studying in a classroom) that I realized how similar IE languages really are and how different, in similar ways, they are to non-IE languages.
I had a general sense of IE but no idea how much we actually have learned about the language and its people through the forensic linguistics you describe so meticulously.
Thanks again. Looking forward to the rest of the series.
Great! I’m glad you discovered the podcast, and I hope you continue to listen and enjoy the story of English. 🙂
Hi Kevin – I have only recently discovered your excellent podcast and am enjoying it very much. I see you started the podcast back in 2012, three years before the first ancient DNA data were published which confirmed that the concensus view you had chosen of steppe PIE origins and Bronze Age IE transmission into central and western Europe by migrations was correct! It is fascinating to see how the three disciplines of Indo-European language studies, archaeology and genetics have gradually converged on that concensus view over the last 30 years or so with Ancient DNA and archaeology finally providing a robust basis for the chronology.
Thank you for your extremely interesting podcast.
Thanks! I’m glad you’re enjoying the podcast series. I’m also happy that the DNA evidence largely confirms the narrative I presented in these episodes. I didn’t want to go back and re-do these episodes. 😉
I, too, am loving this podcast, for the reasons others here have stated, and because I love words and finding out where they come from.
I happen to also be listening to “The British History Podcast” alongside this one, and enjoying the connections between the two.
Thank you for the map you have included for today’s episode. It was just what I was after.
And I am impressed that you have continued to reply to posts seven years after you made this episode!
Thanks! I’m glad you’re enjoying the podcast. And The British History Podcast is a great deep-dive into the political and cultural history of the period. I also recommend David Crowther’s History of England podcast. Both podcasts are great resources.
Interestingly, the Gathas (as well as the Yasnas and Yashts) can be interpreted using Vedic Sanskrit, the language of the Vedas, as the Rig Veda is composed in a closely related language. Many words bear a close resemblance. Both the Rig Veda and the Gathas make references to deities/spirits using the same word: devas in the Rig Veda and daevas in the Gathas. Another example is the reference to demons (asura in the Rig Veda) or gods (ahura, which is an Avestan god in the Gathas). In the Rig Veda the devas are worshipped as gods and the asuras are put down as demons, while in Zoroastrianism ahuras are the gods and daevas are the demons. The treatment of these deities are reversed. Both texts use almost the exact same terms for a member of a religious sodality (Aryaman in the Rig Veda and Airyaman in the Gathas), for sacrifice (yajna in the Rig Veda and yasna in the Gathas), and for a fire priest (Atharvan in the Rig Veda and Athaurvan in the Gathas), fire being a sacred symbol in both religions. Both texts seem to speak of the same set of deities and characters. Indeed, speakers of both language subgroups used the same word to refer to themselves as a people: Vedic Sanskrit arya and Avestan/Old Persian ariya. Both words “a-ve-sta” and “ve-da” are derived from the same root: “Vid” to know, to gain knowledge. This word “Vae-da” also appears in the Gathas (Yasna 28.10, Yasna 31.2) as knowledge. Similarly the term Avesta is called Upastha in Vedic Sanskrit, meaning collection of mantras, or sacred utterances. The chief difference between the two lies in certain well-defined phonetic shifts rather than in basic grammar. It is, therefore, quite possible, by simple phonetic substitutions, to transliterate verses from the Gathas into intelligible Vedic Sanskrit.
This is an English language story but since we are talking of cognates in general, Russian has a whole bunch based on Sanskrit word Veda. Povedat’ (Поведать) to tell/explain; Nevezhda(Невежда) an ignorant person, a know nothing (notice the negative ne (neyt) at the front) Zavédushij (Заведующий) a person in charge of property or people a manager.
Regarding the point made about loan words in relation to Hungarian: yes Hungarian borrowed many words from Indo-European languages.
The Hellenic word “discos” migrated into the Latin “discus” and then evolved into “desko” in old Italian (which became the word for “dinner table” in modern Italian), and passed into middle English to become “desk”, AND it also passed into proto-Slavic “dъska” which then passed into the Hungarian “deszka” (borrowed from the proto-Slavic “dъska”).
Quite possibly, as the Hungarians were the newest nomadic group to have come into Europe, and thereby the newest who carried absolutely no food along with them, there was no “table” to speak of.
The Han Chinese encountered these nomadic people, there were stories of the “Xiongnu” invaders who carried absolutely no food along with them. So when they settled in modern Hungary, they borrowed the word “”deszka” to reflect a new cultural change in lifestyle.
There are Hungarian terms borrowed from Sanskrit, like the Hungarian word dévadászi from the Sanskrit देवदासी (devadāsī, “female servant of a deity”), from देव (deva, “deity”, “god”) + दासी (dāsī, “a female servant or slave”). Also, the Hungarian word sztúpa from Sanskrit स्तूप (stūpa, “heap” or some kind of mound-like structure). Interestingly, stupas, as mound-like structures, refers to containing Buddhist relics, typically the ashes of Buddhist monks, used by Buddhists as a place of meditation.
The traditional view holds that the Hungarian language diverged from its Ugric relatives in the first half of the 1st millennium BC, in western Siberia east of the southern Urals. The Hungarians gradually changed their lifestyle from being settled hunters to being nomadic pastoralists, probably as a result of early contacts with Iranian (Scythians and Sarmatians) or Turkic nomads. In Hungarian, Iranian loanwords date back to the time immediately following the breakup of Ugric and probably span well over a millennium. Among these include tehén ‘cow’ (cf. Avestan dhaénu); tíz ‘ten’ (cf. Avestan dasa); tej ‘milk’ (cf. Persian dáje ‘wet nurse’); and nád ‘reed’ (from late Middle Iranian; cf. Middle Persian nāy).
Archaeological evidence from present day southern Bashkortostan confirms the existence of Hungarian settlements between the Volga River and the Ural Mountains. The Onoğurs (and Bulgars) later had a great influence on the language, especially between the 5th and 9th centuries. This layer of Turkic loans is large and varied (e.g. szó “word”, from Turkic; and daru “crane”, from the related Permic languages), and includes words borrowed from Oghur Turkic; e.g. borjú “calf” (cf. Chuvash păru, părăv vs. Turkish buzağı); dél ‘noon; south’ (cf. Chuvash tĕl vs. Turkish dial. düš). Many words related to agriculture, state administration and even family relationships show evidence of such backgrounds. Hungarian syntax and grammar were not influenced in a similarly dramatic way over these three centuries.
After the arrival of the Hungarians in the Carpathian Basin, the language came into contact with a variety of speech communities, among them Slavic, Turkic, and German. Turkic loans from this period come mainly from the Pechenegs and Cumanians, who settled in Hungary during the 12th and 13th centuries: e.g. koboz “cobza” (cf. Turkish kopuz ‘lute’); komondor “mop dog” (< *kumandur < Cuman). Hungarian borrowed many words from neighbouring Slavic languages: e.g. tégla ‘brick’; mák ‘poppy’; karácsony ‘Christmas’.
Recent studies support an origin of the Uralic languages, including early Hungarian, in eastern or central Siberia, somewhere between the Ob and Yenisei river or near the Sayan mountains in the Russian–Mongolian border region. A 2019 study based on genetics, archaeology and linguistics, found that early Uralic speakers arrived from the East, specific from eastern Siberia, to Europe.
Today the consensus among linguists is that Hungarian is a member of the Uralic family of languages. However, during the latter half of the 19th century, a competing hypothesis proposed a Turkic affinity of Hungarian, or, alternatively, that both the Uralic and the Turkic families formed part of a superfamily of Ural–Altaic languages. Following an academic debate known as Az ugor-török háború ("the Ugric-Turkic war"), the Finno-Ugric hypothesis was concluded the sounder of the two.
Hungarians did in fact absorb some Turkic influences during several centuries of cohabitation. For example, the Hungarians appear to have learned animal husbandry techniques from the Turkic Chuvash people, as a high proportion of words specific to agriculture and livestock are of Chuvash origin. A strong Chuvash influence was also apparent in Hungarian burial customs.
Where did the term "Hungarian" come from? In the old Chinese pronunciations, the word for "Xiong" ~ is pronounced something like "Hun" or "Hunn" . The world "Xiongnu" in old and Middle Chinese sounds/pronounced like "Hunnu" or “Hyong nu”. The Turkic people also say "Hunnu".
How do the Chinese spell "Hungarian"? In Chinese, 匈牙利 or Xiōngyálì. In Chinese, Xiongnu=匈奴, Hun=匈, Hungarian=匈牙利, all of them use the same character "匈" At some point, someone translated "匈" as "hun", linking hun to Xiongnu.
"X" is the palatalization of "H". "Xiong" would have been "Hiong". In ancient Chinese history documents , Xiong =Hun , Nu= Slave. Xiong nu is means something like "fierce slave".
According to Chinese sources there were infighting among the princes/chieftain themselves when their leader pass away. And some steppe confederate who conscript to be meat soldier used this opportunity to break away. Some chieftain seek official support from the Han court and their allies, which they did and win. The one that lost migrated far west and continue to displace the existing population and assimilate the losing side army. By continuous warfare, the nomadic steppes people absorb more soldiers into their rank. The winning Xiong nu faction settled down, some turn to semi agriculture/herding/trading and continue to have favorable trading concession from Han court.
Love this series!!! I plan to listen to the entire series before asking questions, but in this episode, at around the 00:31:00 mark, you have a repeated paragraph.
Thanks for the note! I recently re-recorded this episode and I missed that edit. I’ve been re-recording some of the early episodes to clean up the audio and fix a problem with the sampling rate that creates problems with some media players. If you spot any other errors, let me know. 🙂
I think maybe this happened in the re-recording because this is the 4th time I have listened to it and the first time I noticed it!
This is an amazing podcast. It’s truly a public service to have all this information gathered together in one easy to listen to format. Thank you for doing the show.
Thank you for listening. I’m glad you’re enjoying it.
I am really enjoying this podcast. I have always loved words and history but few in my family have shared that love. Imagine my surprise when several of my daughters told me they were listening to your podcast. One of them had it on in her car while she was driving me home and here I am still listening. Thank you for this series.
Fun for the whole family! I’m glad all of you are enjoying the podcast.
I just discovered this podcast this week and I love it. Are there transcripts anywhere?
Never mind, found the transcripts!
I’m a listener of advisory opinions. I also have a Masters of Divinity which exposes you to some Ancient Near Eastern history. This podcast is excellent. Has given me a greater appreciation for the history of the English language. Thank you!
“All of these trade routes met just south of the area between the Black Sea and the Mediterranean in what came to be known as the Middle East, also known as ‘the crossroads of the ancient world’ for obvious reasons.
So we have the Mediterranean, Black Sea, Caucasus Mountains and Caspian Sea forming a east-west barrier inhibiting travel, except for a narrow passage between the Mediterranean and the Black Sea.”
I see why you said, early on, that this is an east/west story! Amazing that this narrow strait became a trade route. And how did people hear about it…
I discovered this podcast only 3 days ago and I absolutely love it. I saw that you suggested reading “The Horse, the Wheel, and Language: How Bronze-Age Riders from the Eurasian Steppes Shaped the Modern World”. Could you suggest other books that I can read if I want to dig deep into the history of the Indo-Europeans? Thank you so much for his gem!
I just discovered this podcast this January while listening to the History and Literature podcast. I love your work here. In the late 1960s to mid 1970 I was a young college professor teaching courses in logic, linguistics and the history of the English language. I stepped away from that world in 1979 to get into computer programming and stayed there until I retired two years ago.
While there is content here that I remember from my previous teaching experience, I am just overwhelmed with the “new” techniques, the new cross-disciplinary work and just how much has been added to our understanding of the History of the English Language. I am remembering much, but learning much, much more new information! This the perfect retirement experience for these cold winter days and nights when I can’t be outside and it gives me something pleasant to think about in the evenings before I fall asleep. Again, thank you! Please keep up the good work.
Thank you. I’m glad you’re enjoying the podcast.
Im glad I’ve found this fantastic series. I’m nerdy enough to be obsessed about the history of words, and the detailed presentation of Indo-European words, grammar and history is gobsmacking in its detail and its clarity.
Thank you Kevin